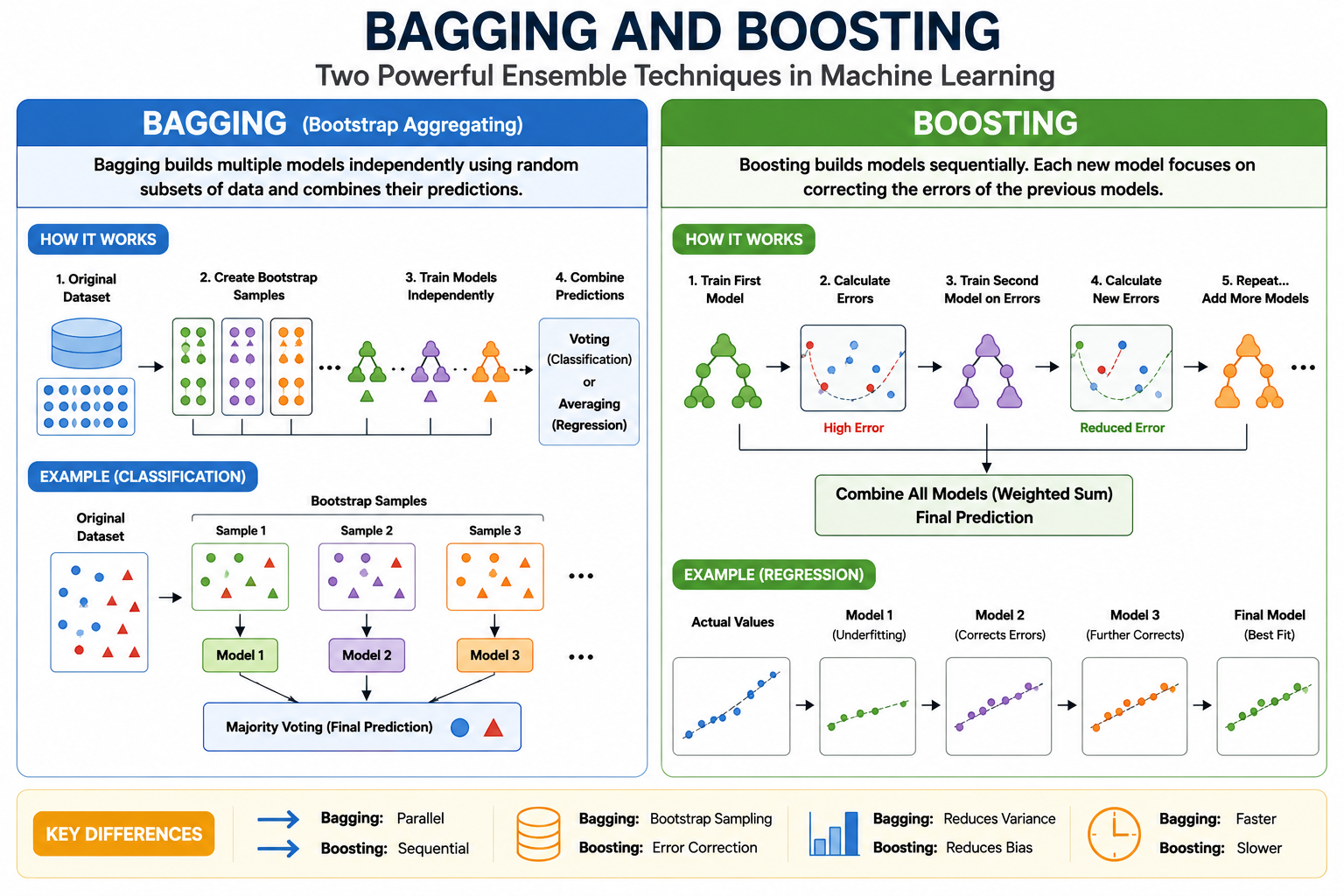
Bagging and Boosting
Bagging and Boosting are two important ensemble learning techniques in machine learning.
Ensemble learning means:
Combining multiple models to create a stronger model.
Instead of depending on one model:
Many models work together to improve accuracy.
What is Bagging?
Bagging stands for:
Bootstrap Aggregating
Bagging creates multiple models independently using random subsets of the training data.
Final prediction is obtained by combining all model outputs.
Main Idea of Bagging
Train many models independently
Combine their predictions
Reduce variance and overfitting
All models work in parallel.
How Bagging Works
1. Create multiple random datasets from original data
2. Train separate models on each dataset
3. Make predictions using all models
4. Combine predictions
Bootstrap Sampling
Bootstrap means:
Random sampling with replacement
Some records may appear multiple times.
Some records may not appear at all.
Example of Bagging
Original Dataset:
| Data |
|---|
| A |
| B |
| C |
| D |
| E |
Bootstrap samples:
Model 1:
A, B, C, D, E
Model 2:
A, A, C, D, E
Model 3:
B, C, C, D, E
Each model trains independently.
Final Prediction in Bagging
For classification:
Majority Voting
For regression:
Average Prediction
Advantages of Bagging
Reduces variance
Reduces overfitting
Improves stability
Works well with decision trees
Disadvantages of Bagging
Higher computation
Less interpretable
Does not reduce bias much
Popular Bagging Algorithm
Random Forest
Random Forest is a bagging-based ensemble of decision trees.
What is Boosting?
Boosting is another ensemble learning technique.
Unlike bagging:
Models are trained sequentially.
Each new model tries to correct the mistakes made by previous models.
Main Idea of Boosting
Model 1 makes prediction
Model 2 corrects Model 1 errors
Model 3 corrects Model 2 errors
...
Final prediction is the combination of all models.
How Boosting Works
1. Train first weak model
2. Calculate errors
3. Train second model on errors
4. Correct previous mistakes
5. Repeat sequentially
6. Combine all models
Example of Boosting
Suppose actual values are:
| X | Actual |
|---|---|
| 1 | 10 |
| 2 | 12 |
| 3 | 14 |
| 4 | 16 |
First model predictions:
| X | Prediction |
|---|---|
| 1 | 13 |
| 2 | 13 |
| 3 | 13 |
| 4 | 13 |
Errors:
| X | Error |
|---|---|
| 1 | -3 |
| 2 | -1 |
| 3 | 1 |
| 4 | 3 |
Second model learns these errors.
Thus:
Each model focuses on remaining mistakes.
Advantages of Boosting
High prediction accuracy
Reduces bias
Learns complex patterns
Very powerful for tabular data
Disadvantages of Boosting
Sensitive to noise
Can overfit
Sequential training is slower
More hyperparameters
Popular Boosting Algorithms
AdaBoost
Gradient Boosting
XGBoost
LightGBM
CatBoost
GBRT
Difference Between Bagging and Boosting
| Bagging | Boosting |
|---|---|
| Models trained independently | Models trained sequentially |
| Parallel learning | Sequential learning |
| Reduces variance | Reduces bias |
| Uses bootstrap sampling | Uses error correction |
| Models have equal importance | Later models focus more on errors |
| Faster training | Slower training |
| Example: Random Forest | Example: XGBoost |
Simple Understanding
Bagging
Many independent models vote together.
Boosting
Many models learn from previous mistakes.
Summary
Bagging builds independent models in parallel to reduce variance, while Boosting builds sequential models that correct previous errors to improve accuracy.