Stochastic Gradient descent classifier
Before understanding the SGD Classifier, you should know that it is not a separate classification algorithm like SVM or Logistic Regression.
Instead:
SGD (Stochastic Gradient Descent) is an optimization technique used to train linear classifiers efficiently on large datasets.
The SGD Classifier in Scikit-Learn can train:
-
Linear SVM
-
Logistic Regression
-
Perceptron
-
Modified Huber Classifier
by changing the loss function.
Why Do We Need SGD?
Suppose we have a dataset with:
1,000,000 records
Traditional algorithms process the entire dataset before updating model parameters.
This becomes:
Slow
Memory intensive
Computationally expensive
SGD solves this problem.
Instead of using all training samples together:
Use one training example at a time
Update weights immediately
Move to next example
This makes learning much faster.
Core Idea of SGD
The main idea is:
Update model parameters after seeing each training sample.
Instead of:
Entire Dataset
↓
Compute Error
↓
Update Weights
SGD performs:
Sample 1
↓
Update Weights
Sample 2
↓
Update Weights
Sample 3
↓
Update Weights
and so on.
What is Gradient Descent?
Gradient Descent is an optimization algorithm used to minimize a loss function.
Imagine standing on a mountain and trying to reach the lowest point.
Current Position
↓
Check Slope
↓
Move Downhill
↓
Repeat
Eventually:
Minimum Error
is reached.
This is exactly how machine learning models learn.
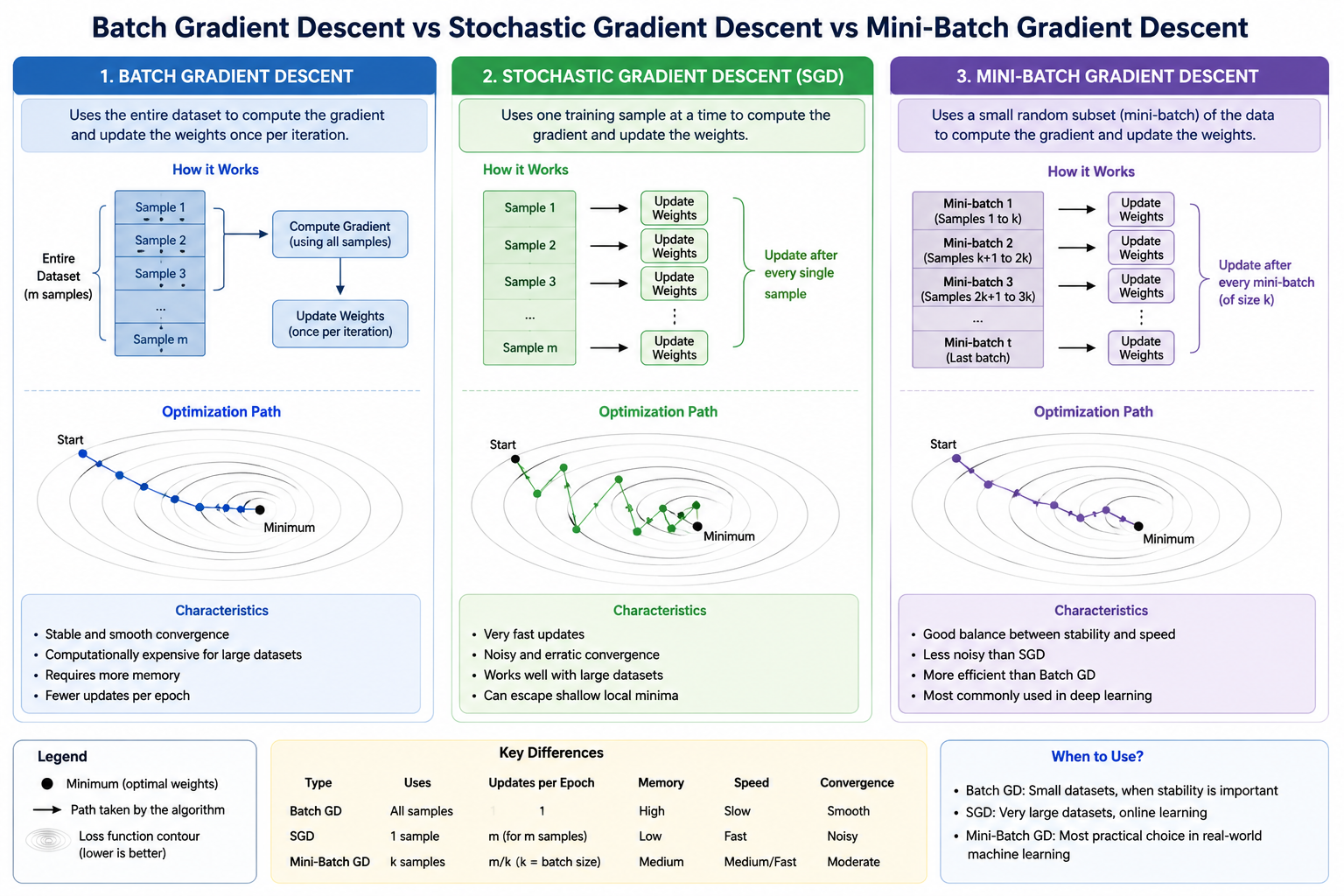
Types of Gradient Descent
1. Batch Gradient Descent
Uses:
Entire Dataset
before updating weights.
Example:
1000 records
↓
Calculate Loss
↓
Update Once
Advantages:
-
Stable updates
Disadvantages:
-
Slow for large datasets
2. Stochastic Gradient Descent (SGD)
Uses:
One Training Sample
at a time.
Example:
Record 1 → Update
Record 2 → Update
Record 3 → Update
Advantages:
-
Fast
-
Memory efficient
Disadvantages:
-
Noisy updates
3. Mini-Batch Gradient Descent
Uses:
Small Groups of Samples
Example:
Batch Size = 32
Updates after every 32 samples.
Most modern deep learning systems use this approach.
How SGD Classifier Works
Suppose we have:
| Study Hours | Pass |
|---|---|
| 2 | 0 |
| 4 | 0 |
| 6 | 1 |
| 8 | 1 |
Initial weights:
w = 0
b = 0
Step 1: Take First Sample
x = 2
y = 0
Predict output.
Calculate error.
Update weight.
Step 2: Take Second Sample
x = 4
y = 0
Predict.
Calculate error.
Update weight again.
Step 3: Continue
x = 6
y = 1
x = 8
y = 1
Weights keep improving after each sample.
Eventually:
Optimal Weights
are obtained.
Weight Update Formula
The SGD update rule is:
wnew=wold−η∇J(w)
Where:
η = Learning Rate
∇J(w) = Gradient of Loss Function
w = Weight
Learning Rate
Learning rate controls:
How big a step is taken
during optimization
Small Learning Rate
Slow Learning
More Accurate
Large Learning Rate
Fast Learning
May Overshoot Minimum
Loss Functions Supported by SGDClassifier
Different loss functions make SGD behave like different classifiers.
| Loss Function | Equivalent Algorithm |
|---|---|
| hinge | Linear SVM |
| log_loss | Logistic Regression |
| perceptron | Perceptron |
| modified_huber | Robust Classifier |
Example:
loss='hinge'
acts like:
Linear SVM
Important Parameters
loss
Defines the learning objective.
Examples:
loss='hinge'
loss='log_loss'
loss='perceptron'
learning_rate
Controls optimization speed.
max_iter
Number of training iterations.
Example:
max_iter=1000
alpha
Regularization strength.
Helps reduce overfitting.
Python Implementation
from sklearn.linear_model import SGDClassifier
X = [[1,1],
[2,2],
[4,4],
[5,5]]
y = [0,0,1,1]
model = SGDClassifier(
loss='hinge',
max_iter=1000,
random_state=42
)
model.fit(X, y)
prediction = model.predict([[3,3]])
print(prediction)
Advantages
-
Very fast on large datasets
-
Memory efficient
-
Supports online learning
-
Works well with sparse data
-
Can train multiple linear models
Limitations
-
Sensitive to learning rate
-
Training can be noisy
-
May not converge to exact optimum
-
Requires feature scaling
Applications
-
Text classification
-
Spam detection
-
Sentiment analysis
-
Large-scale machine learning
-
Online learning systems
-
Recommendation systems
Summary
Important Points
-
SGD stands for Stochastic Gradient Descent.
-
SGD is an optimization technique, not a standalone classification algorithm.
-
It updates model weights after each training sample.
-
SGD is faster than Batch Gradient Descent for large datasets.
-
Learning rate controls optimization speed.
-
SGDClassifier can implement Linear SVM, Logistic Regression, and Perceptron.
-
It is widely used for large-scale machine learning problems.
-
Feature scaling is important for better convergence.
Keywords
Stochastic Gradient Descent, SGD Classifier, Gradient Descent Optimization, Online Learning, Learning Rate, Batch Gradient Descent, Mini Batch Gradient Descent, SGD Optimization, Linear Classifier Training, Machine Learning Optimization



