Support Vector Regression
Support Vector Regression (SVR) is a supervised machine learning algorithm used for regression problems.
SVR is based on: Support Vector Machine (SVM)
but instead of classification, SVR predicts: Continuous numerical values
Idea of SVR
Unlike Linear Regression:
Which tries to minimize prediction error directly
SVR tries to:
Fit the best line within a margin of tolerance
Real-Life Example
Suppose we want to predict:
-
House prices
-
Stock prices
-
Temperature
-
Sales forecasting
SVR helps create a regression model that:
-
Handles nonlinear patterns
-
Reduces overfitting
-
Maintains robustness
Understanding the SVR Concept
SVR does NOT try to fit every data point exactly.
Instead:
It tries to keep prediction errors within a fixed boundary
called:
Margin or Epsilon (ε)
Epsilon Margin
SVR creates:
A margin around the regression line
If prediction errors fall inside this margin:
No penalty is applied
Only points outside the margin affect the model.
Important Components of SVR
| Component | Meaning |
|---|---|
| Hyperplane | Regression line |
| Support Vectors | Important data points |
| Margin | Allowed error boundary |
| Epsilon (ε) | Tolerance limit |
Simple Visualization
You can imagine:
-
A regression line in the center
-
Two parallel boundary lines
-
Errors inside the boundary are acceptable
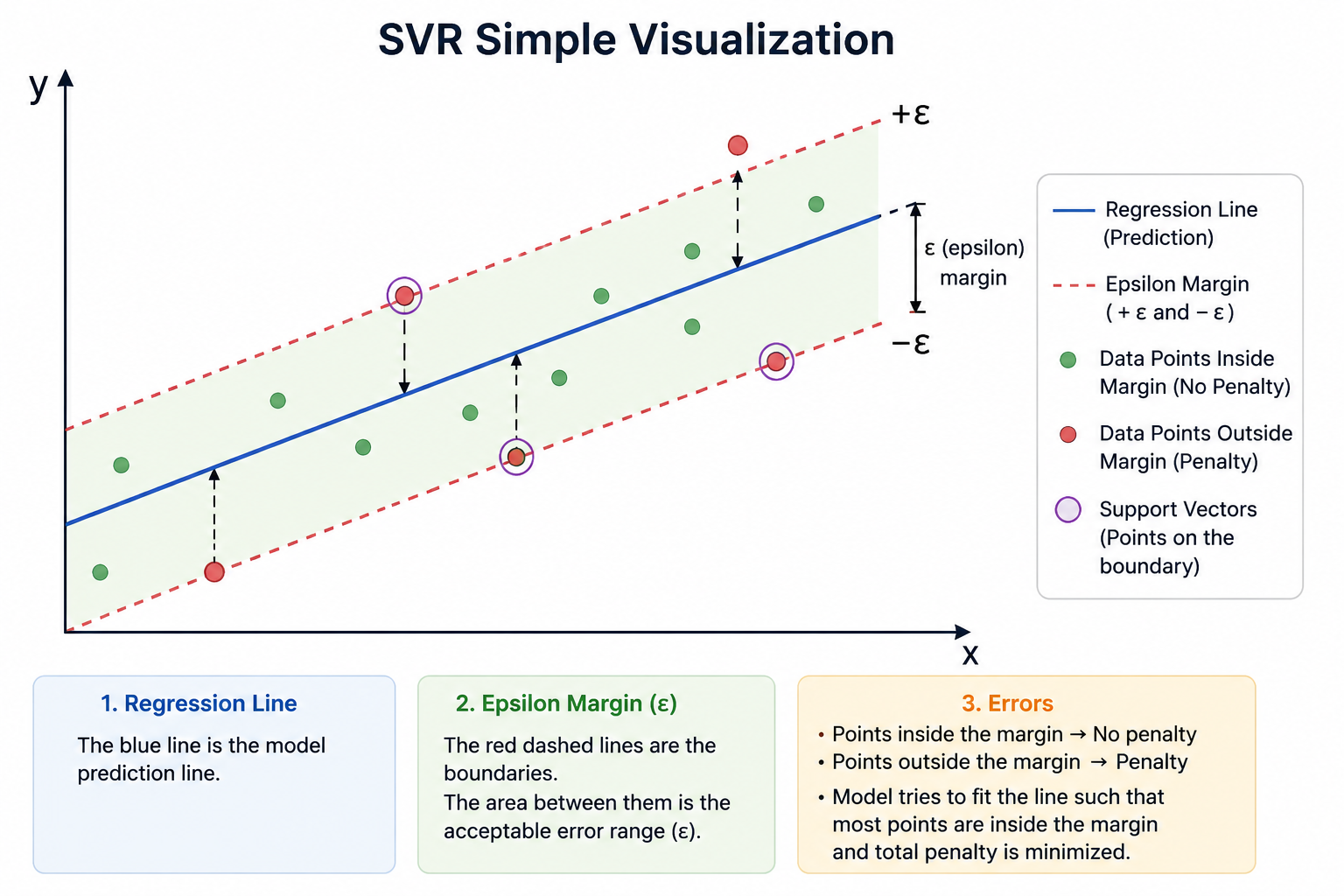
The above diagram explains the basic idea of Support Vector Regression (SVR). The blue line in the center represents the regression prediction line. The two red dashed lines represent the epsilon margin, which defines the acceptable error range. Data points that fall inside this margin are considered acceptable, so SVR does not apply any penalty to them. Points outside the margin create prediction errors and are penalized by the model. The circled points near the boundary are called support vectors, and these points play an important role in determining the position of the regression line. The main goal of SVR is to fit a line such that most data points remain inside the epsilon margin while minimizing overall prediction error.
Why SVR is Powerful
SVR:
-
Handles nonlinear relationships
-
Works well with small datasets
-
Reduces overfitting
-
Focuses only on important points
Support Vectors
Support vectors are:
Data points closest to the boundary
These points:
-
Control the regression line
-
Influence model predictions
SVR Regression Equation
Basic idea:
y = wx + b
Where:
-
w → Weight
-
b → Bias
But SVR optimizes:
Margin and prediction tolerance
instead of only minimizing error.
Epsilon (ε) Concept
Suppose:
ε = 5
Then:
-
Errors within ±5 are ignored
-
Only larger errors are penalized
Example Dataset
| Experience | Salary |
|---|---|
| 1 | 15 |
| 2 | 20 |
| 3 | 28 |
| 4 | 40 |
| 5 | 60 |
SVR tries to:
Fit a smooth prediction line with tolerance
Kernel Trick in SVR
SVR can handle nonlinear data using:
Kernel Functions
Popular kernels:
-
Linear Kernel
-
Polynomial Kernel
-
RBF Kernel
RBF Kernel
Most commonly used kernel:
Radial Basis Function (RBF)
It helps model:
Complex nonlinear patterns
Important Hyperparameters
| Parameter | Meaning |
|---|---|
| C | Controls penalty |
| epsilon | Margin width |
| kernel | Type of curve fitting |
Understanding C Parameter
Small C:
Wider margin
More tolerance
Large C:
Smaller margin
Less tolerance
Practical Example Using Python
Step 1: Import Libraries
import pandas as pd
from sklearn.svm import SVR
Step 2: Create Dataset
data = {
"Experience": [1, 2, 3, 4, 5],
"Salary": [15, 20, 28, 40, 60]
}
df = pd.DataFrame(data)
print(df)
Step 3: Define Features and Target
X = df[["Experience"]]
y = df["Salary"]
Step 4: Create SVR Model
model = SVR(kernel='rbf')
Step 5: Train Model
model.fit(X, y)
Step 6: Predict New Value
Predict salary for:
Experience = 6
prediction = model.predict([[6]])
print(prediction)
Example Output
[58.4]
Why Feature Scaling is Important
SVR is highly sensitive to feature scales.
So:
Feature Scaling is strongly recommended
before using SVR.
Advantages of SVR
-
Handles nonlinear data
-
Robust against outliers
-
Works well with small datasets
-
Good generalization performance
Limitations
-
Training can be slow for large datasets
-
Parameter tuning is important
-
Scaling is required
Real-World Applications
| Industry | Usage |
|---|---|
| Finance | Stock price prediction |
| Healthcare | Medical prediction |
| Sales | Revenue forecasting |
| Weather | Temperature prediction |
Important Points
1. SVR is based on Support Vector Machine.
2. SVR predicts continuous numerical values.
3. SVR uses epsilon margin for tolerance.
4. Support vectors influence the regression line.
5. Kernel functions help model nonlinear data.
Summary
Support Vector Regression (SVR) is a powerful regression algorithm that predicts continuous values using support vectors and margin-based optimization. It is effective for nonlinear regression problems and uses kernel functions to model complex relationships in data.
Keywords
Support Vector Regression, SVR, Support Vector Machine Regression, SVR in Machine Learning, Regression Algorithms, Epsilon Margin, Support Vectors, Kernel Functions, RBF Kernel, Nonlinear Regression, Supervised Learning Regression, Margin-Based Regression, SVR using Python, Scikit Learn SVR, Regression using SVM, Machine Learning Regression



